Media/WebRTC/WebRTCE10S
Introduction
The WebRTC architecture for desktop (Media/WebRTC/Architecture) is based on a single process model where we can directly access platform resources from the WebRTC code. B2G, however, has a split process architecture (B2G/Architecture) where the renderer/content process runs in a sandbox and has limited access to platform resources. Generally, it accesses them by doing IPC calls via https://developer.mozilla.org/en-US/docs/IPDL
The current architectural split is shown below:
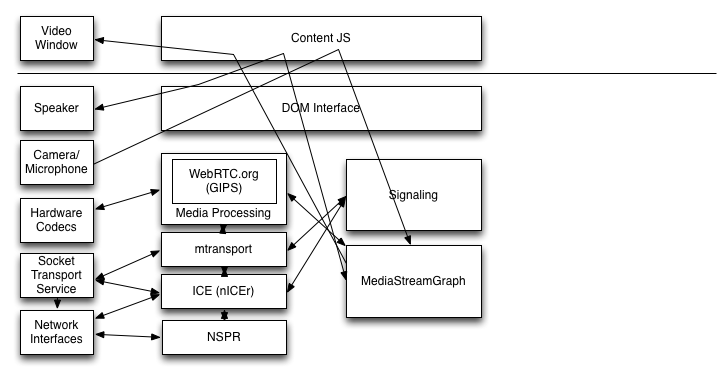
In this diagram, physical devices are shown on the left and components of the browser are on the right. Note that we show a number of arrows going through the DOM/JS layer. The implication is that MediaStreams are mediated by the DOM/JS layer. I.e., JS is responsible for plumbing MediaStreams between gUM and the PeerConnection and between the PeerConnection and video/audio tags. This doesn't mean that the media actually flows through the JS, however.
Below we show a proposed process split with E10S:
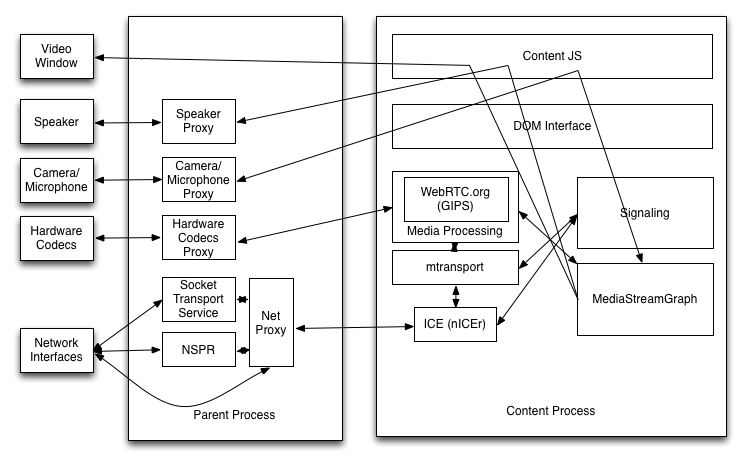
System Resources to be Proxied
The following system resources need to somehow be made accessible to the renderer process.
- Video rendering (accessed via a video tag) [TODO: Is this actually a system resource? Not clear on what the display model is.]
- The speaker (accessed via an audio tag)
- The camera and microphone
- Hardware video encoders and decoders (if any)
- The network interfaces
In addition, we use the Socket Transport Service (STS) to do socket input processing. We create UDP sockets via NSPR and then attach them to the STS in order to be informed when data is available.
Input Device Access (getUserMedia)
We assume that camera and microphone access will be available only in the parent process. However, since most of the WebRTC stack will live in the child process, we need some mechanism for making the media available to it.
The basic idea is to create a new backend for MediaManager/GetUserMedia that is just a proxy talking to the real media devices over IPDL. The incoming media frames would then be passed over the IPDL channel to the child process where they are injected into the MediaStreamGraph.
This shouldn't be too complicated, but there are a few challenges:
- Making sure that we don't do superfluous copies of the data. I understand that we can move the data via gralloc buffers, so maybe that will be OK for video. [OPEN ISSUE: Will that work for audio?]
- Latency. We need to make sure that moving the data across the IPDL interface doesn't introduce too much latency. Hopefully this is a solved problem.
Output Access
[TODO: Presumably this works the same as rendering now?]
Hardware Acceleration
In this design, we make no attempt to combine HW acceleration and capture or rendering. I.e., if we have a standalone HW encoder, we just insert it into the pipeline in place of the the SW encoder and then redirect the encoded media out the network interface. The same goes for decoding. There's no attempt made to shortcut the rest of the stack. This design promotes modularity, since we can just make the HW encoder look like another module inside of GIPS. In the longer term, we may want to revisit this, but I think it's the best design for now.
Note that if we have an integrated encoder (e.g., in a camera) then we *can* accomodate that by just having gUM return encoded frames instead of I420 and then we pass those directly to the network without encoding them. (Though this is somewhat complicated by the need to render them locally in a video tag.)
Network Access
All networking access in WebRTC is mediated through the ICE stack (media/mtransport/third_party/nICEr and media/mtransport/nr*).
From a technical perspective, the requirements look like:
- The ability to send and receive UDP datagrams with any valid local address and any remote address.
- The ability to enumerate every network interface.
- The ability to have events happen at specific times.
Below is a schematic diagram of the interaction of the ICE stack with the rest of the system which shows how things actually work.
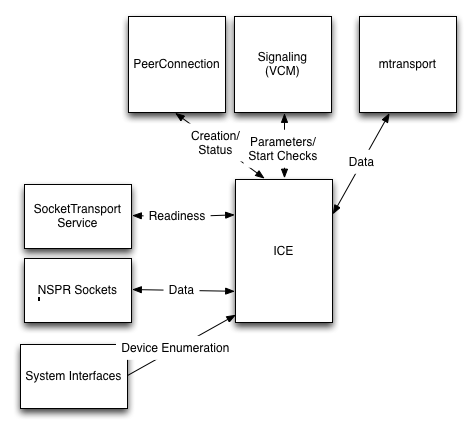
As before, the boxes on the left signify the currently protected operations.
There are two natural designs, discussed below.
Network Proxies
The first design is to do only the primitive networking operations in the parent process and have ICE talk to the proxies that remote those operations, as shown below. This is approximately the design Google uses.
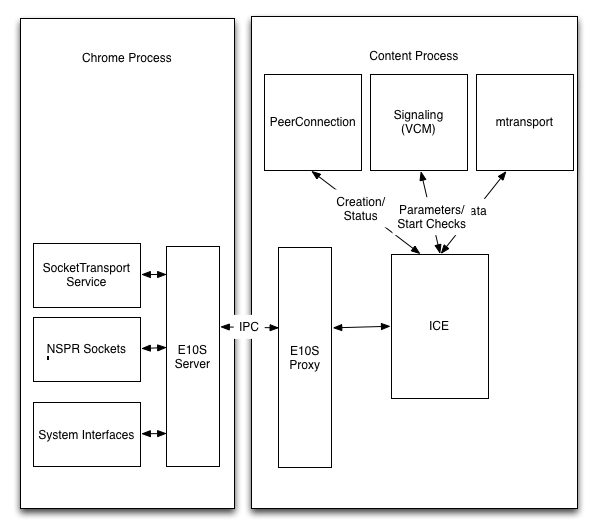
The advantage of this design is that it is relatively straightforward to execute and that the APIs that are required are relatively limited. I.e.,
- List all the interfaces and their addresses
- Bind a socket to a given interface/address
- Send a packet to a given remote address from a given socket
- Receive a packet on a given socket and learn the remote address
The major disadvantage of this design is that it provides the content process with a fair amount of control over the network and thus potentially represents a threat if/when the content process is compromised. For instance, if the content process is compromised, it could send arbitrary UDP or TCP packets to anywhere in the network that is accessible to the phone. Of course, this is already a risk in the desktop version.
We might be able to mitigate this risk somewhat by installing some primitive packet filtering on the parent process side. For instance, we could enforce the following policy:
- A socket maintains two tables:
- An outstanding STUN transaction table
- A "permissions" table of accepted remote addresses
- When a content process tries to send a non-STUN formatted packet, the socket rejects it unless the remote address is in the permissions table
- When a content process sends a STUN-formatted packet, it gets transmitted and added to the outstanding STUN transaction table
- When packet is received, it is checked against the outstanding STUN transaction table. If a transaction completes, then the address is added to the permissions table.
This would be relatively easy to implement and would provide a measure of protection
against misuse of this interface. It would require some STUN-parsing smarts in the
parent, but those can be kept relatively minimal.
Detailed api proposal at Media/WebRTC/WebRTCE10S/NetworkProxyInterface
ICE In Parent
The alternative design is to push the entire ICE stack into the parent process, as shown below.
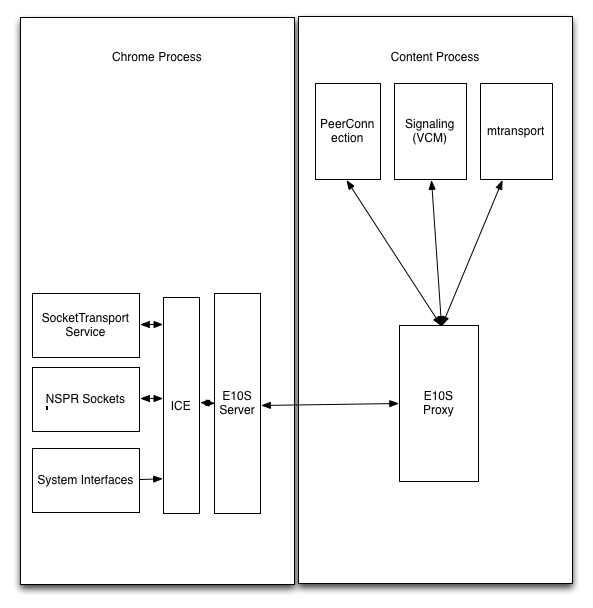
The advantage of this design from a security perspective is that by pushing the connectivity checking into the parent process we completely remove the ability of a compromised content process to send arbitrary network traffic.
The two major drawbacks of this design are:
- The interface to the ICE stack is very complicated, which makes the
engineering task harder.
- The ICE stack itself is also complicated, which increases the surface area
in the "secure" parent process.
The ICE stack interface is found at:
- http://hg.mozilla.org/mozilla-central/file/b553e9ca2354/media/mtransport/nricectx.h
- http://hg.mozilla.org/mozilla-central/file/b553e9ca2354/media/mtransport/nricemediastream.h
This API has around 20 distinct API calls, each of which will need to be separately remoted. A number of them have fairly complicated semantics, which would tend to invade the rest of the program.
Recommendation
In my opinion we should go for the "Network Proxies" design. It's going to be a lot simpler to implement than the "ICE in the parent" design and can be largely hidden by an already replaceable component (nr_socket_prsock.cpp) without impacting the rest of the code. It also lets us work in parallel because we can do a simple implementation without the packet filter described above and then add the packet filter transparently later.